ABOUT
|
|
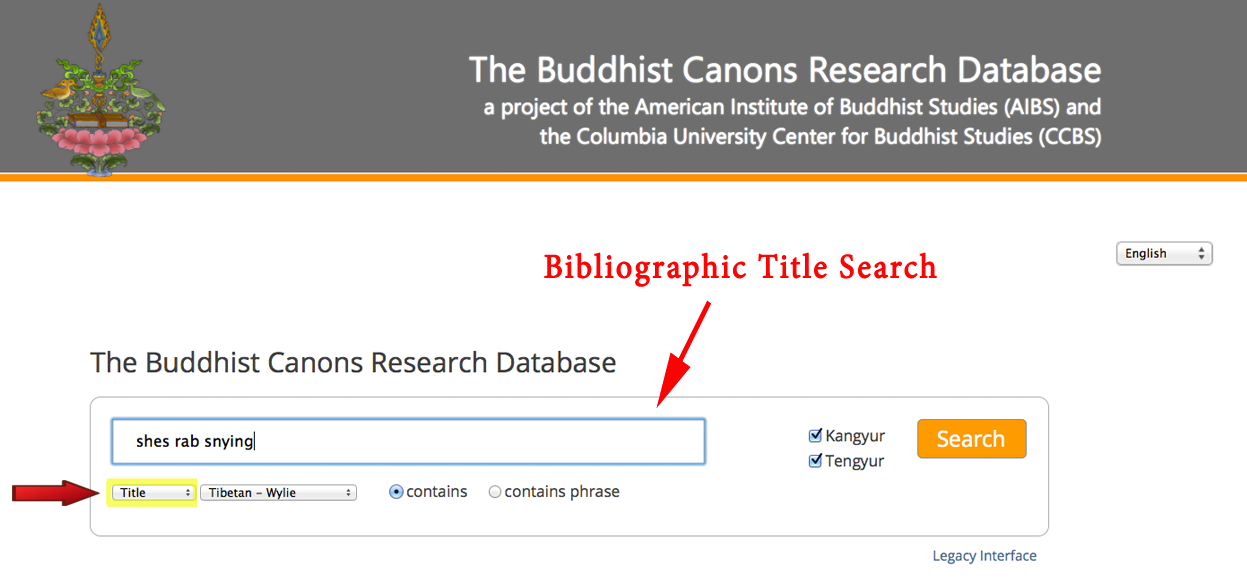
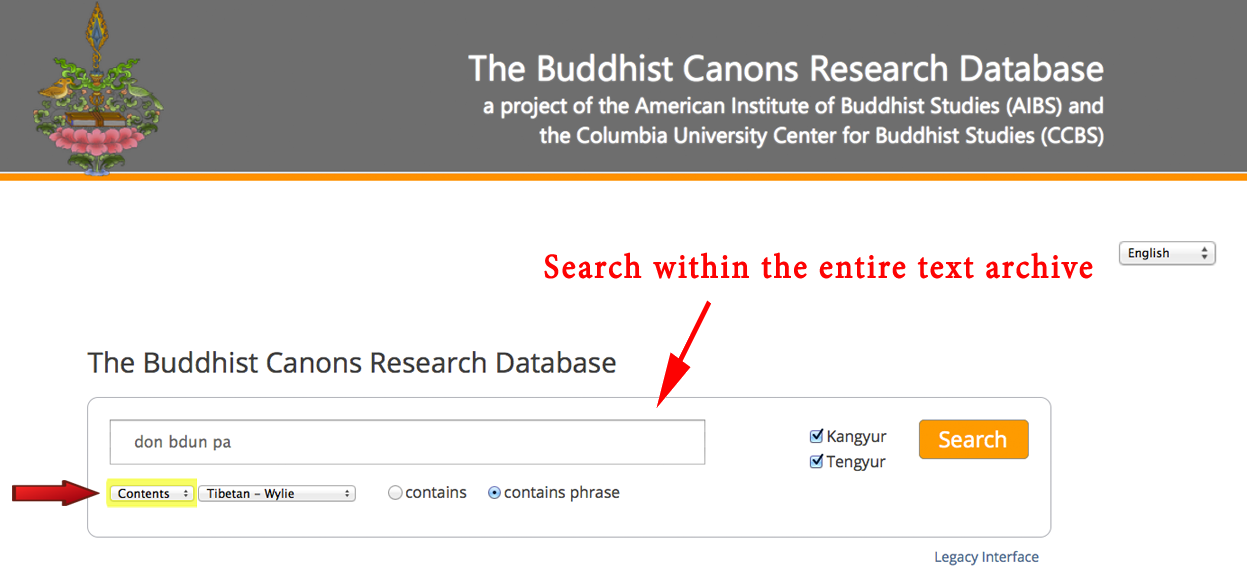
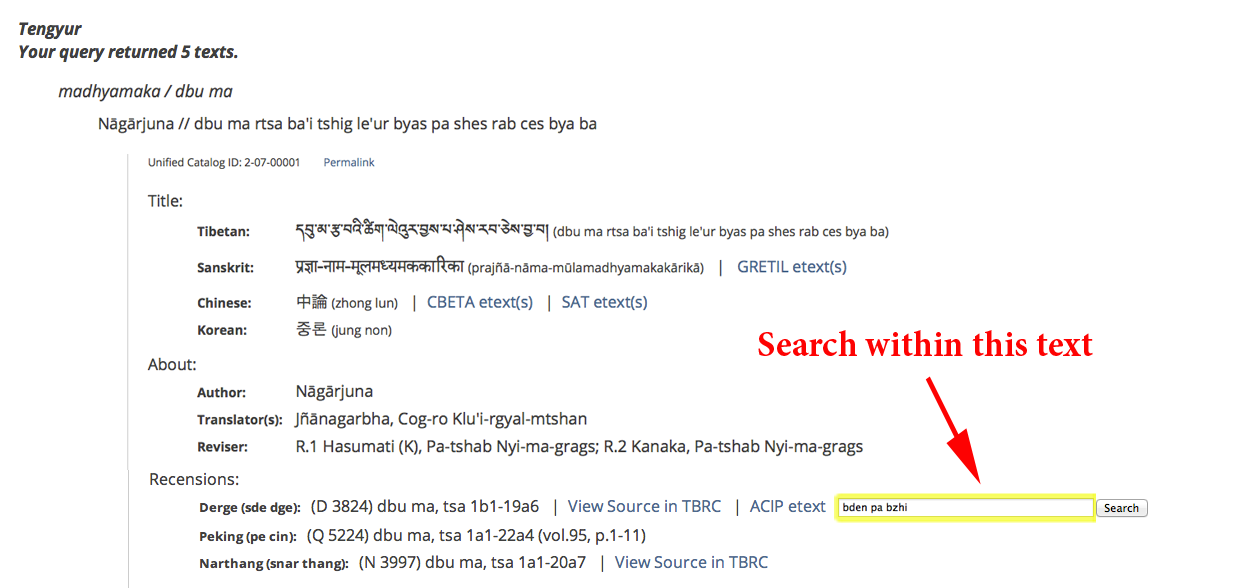
THE BUDDHIST CANONS RESEARCH DATABASEThe Buddhist Canons Research Database is a resource that offers complete bibliographic information (with internal crosslinks and links to external resources) for the roughly 5,000 texts contained in the Tibetan Buddhist canon, and offers both general and targeted full text search access to those texts (approximately 15 million syllables). History The Buddhist Canons Research Database was first developed as a private reference tool in 1994 as a loose combination of existing bibliographies and reference resources. In 1999, a custom search-and-retrieval search engine was built specifically for Tibetan language data, incorporating fuzzy-matching, stemming, and part-of-speech identification in support of corpus-based linguistic research for Tibetan. In 2010, the basic bibliographic database was first deployed (as a public beta) as an online resource to enable the research community to document and track editions and translations of texts in the Buddhist canon — beginning with Tibetan canonical works collected in the Kangyur (bka 'gyur) and Tengyur (bstan 'gyur). Designed to facilitate research in canonical materials, related texts in the two halves of the canon and in the bibliography of secondary literature in world languages were cross-linked to allow for rapid accessing of information, including direct links to page images (hosted by TBRC) and e-text (hosted by ACIP) as well as documentation and links to parallel e-texts in Sanskrit and Chinese. In 2011, in an attempt to support the larger goal of the American Institute of Buddhist Studies (AIBS) of promoting translation and research in Buddhist Studies worldwide, the interface to the database was redesigned for localization in nine languages (English, French, German, Spanish, Dutch, Russian, Tibetan, Japanese, and Chinese). In addition, as one of the key strengths of the Tibetan literature lies in its thousand year commentarial tradition on the Buddhist canon, select authors and textual collections were added to the database as well, providing direct links to Tibetan-authored commentaries on canonical works. This remains an ongoing augmentation of the research database. In 2013, the BCRD was formally launched with a redesigned interface, and full-text searching of the Kangyur and Tengyur — either as a whole or specifically within an individual text — was added, complete with page-by-page reference information and links to available e-text (again hosted by ACIP) and partial lexical information automatically provided through the use of techniques of Natural Language Processing. This, too, remains an ongoing development of the database. A detailed presentation of the latest features was given by Paul Hackett at the Thirteenth Seminar of the International Association for Tibetan Studies (IATS-XIII), Ulaanbaatar, Mongolia, July 2013, and at the "Humanities Studies in the Digital Age and the Role of Buddhist Studies" conference at the University of Tōkyō, November, 2013. HOW TO SEARCH FOR TEXTS IN THE CANONAt the present time, a user can search for texts by Title or Author in one of three languages — Tibetan, Sanskrit, or Chinese — either in script or Romanization (Wylie, ACIP, IAST, HK, or Pinyin). For example, to search for the Heart Sutra, one could search for all texts containing the syllables "shes rab snying" in the Tibetan title (Wylie transcription).
|
The Buddhist Canons Research Database is a project designed and implemented by Paul G. Hackett, who serves as the principal compiler and editor. Dr. Hackett holds a Ph.D. and M.Phil. in Indo-Tibetan Buddhism from Columbia University, an M.L.S. in Information Science from the University of Maryland at College Park, an M.A. in History of Religions from the University of Virginia, and a B.S. in Astronomy and Physics from the University of Arizona. He specializes in canonical Buddhist philosophy and Tibetan culture, as well as their influence on contemporary alternative religion in America; he is also active in the field of computational linguistics and natural language processing of Asian languages, and serves as co-chair (with a colleague in Beijing) of the Tibetan Information Technology Panel for the International Association for Tibetan Studies. |
 |
OUR RESEARCH PARTNERS
The Buddhist Canons Research Database (BCRD) and AIBS have established close working relationships with several other initiatives in the field of Tibetan and Buddhist studies. Our research partners include: the Asian Classics Input Project (ACIP), the Tibetan Buddhist Resource Center (TBRC), the Sastravid Indian Philosophy Research System, and many others as well as numerous affiliated and independent scholars.
Most recently, the Buddhist Canons Research Database and the SAT Daizōkyō Text Database (大藏經テキストデータベース研究会) at the University of Tōkyō have established protocols for interlinking of the respective databases as a first step towards allowing seemless sharing of information between the two resources and a unified cataloging system for Tibetan and Chinese Buddhist texts.